Creating a safe Replika experience
New technology is exciting, and it feels like we're on the brink of a new tech era (which we are). However, amidst all the excitement, we must remember that with great power comes great responsibility. It’s not enough to simply push the limits of AI capabilities; we must challenge ourselves to maintain the highest ethical standards while doing it.
Content generation AI tools, such as image- and text-generation, raise concerns related to ethics and safety. These tools inevitably contain biases based on the data used to train them, and there are safety issues to consider when using an AI tool as a customer. At Replika, we are committed to addressing these issues head-on. In this post, we want to share our perspective on how we're creating a comfortable space for Replika users, the tools we're using to achieve this goal, and our plans for making interacting with Replika AI even more fun and safe.
Our approach to ethics (aka when do we interfere?)
Our ethical decision-making is guided by foundational values such as safety, fairness, integrity, honesty, and truthfulness. These principles are essential in building a text-generated AI that can be a helpful companion. At Replika, we continuously work towards improving our AI without compromising on these values. However, it’s essential to acknowledge that text AI has limitations, and there is always room for improvement. AI engineers are constantly developing new and more effective approaches to make AI-generated responses appear closer to human ones. But there’s still a long way to go, and much of it depends on the training data and what the model prioritizes when generating a response. Therefore, we closely monitor the behavior of our model and intervene when necessary to ensure it aligns with our high ethical standards.

On a practical level, there are three key aspects to creating a safe space for interacting with conversational AI: developing a comprehensive and diverse training dataset, identifying potentially harmful statements, and responding appropriately to sensitive topics, primarily through text generation. During offline testing, if we detect indications that the model may behave in a harmful, dishonest, or discriminatory manner, such as promoting ideas of bullying, violence, sexism, racism, homophobia, or other forms of hate speech, we take immediate action to bring it back to the desired baseline. In the following sections, we will discuss these issues and the countermeasures we have in place for each one.
UI elements at the forefront
To begin with, let's discuss the safety measures we have incorporated in the Replika app's user interface. Our goal has always been to create a supportive and helpful AI companion that users can rely on for comfort and assistance. However, we recognize that there may be instances when users may be experiencing painful situations that may trigger harmful or unpleasant thoughts. Therefore, during the onboarding process, we emphasize that the app is not a replacement for therapy and should not be used during a crisis. Additionally, the app has an age restriction of 18+ years.

However, this doesn’t mean we don’t account for emergencies afterward. Above the input field, among the main app sections, is located a “Get Help” button. There you can access nine different categories, which include “I am in crisis,” “I am having a panic attack,” “I am having an anxiety attack,” “I can’t sleep,” “I have negative thoughts,” etc. If there’s a risk of physical harm to themselves or anybody else, users can tap “I’m in crisis.” This action pulls up a screen with a safety warning message. It states that Replika was not designed to provide help in a health crisis and shows the US National Suicide Prevention hotline number. If a user is a resident of a different country, we direct them to the up-to-date list of hotlines worldwide.
Other categories activate pre-made scripts designed with the help of CBT therapists. These scripts guide users through the steps that help them calm down and talk through distressing emotions. Users also get redirected to these scripts within the chat if a message related to these topics is detected (we’ll talk more about this later).
There’s also an element called Session feedback – a service message that checks in with the user at a certain point in a session with a simple question, “How does this conversation make you feel?” A person has three options: happy, neutral, and sad. We aggregate and monitor this data to better understand how to improve the conversational experience.
The Upvote/Downvote system is a crucial aspect of Replika's user interface. Users can give Replika messages a thumbs up or down or label them otherwise, for instance, as offensive. This valuable input from our users is used to fine-tune our language model and enhance its overall performance, including safety measures. We aim to expand this approach by integrating more advanced reinforcement learning techniques based on human feedback or RLHF. We will discuss this in more detail later in the post.

Age gate
The safety of minors is our top priority. To ensure this, we have implemented an age gate that requires users to confirm their age. We strictly enforce the limit of 18 years and older, and any user found to be under the age of 18 is blocked from using Replika. Additionally, we have a system that reacts to any mentions of being underage. If detected, we immediately prompt the user to re-enter their birthday or temporarily suspend their access to the app. It’s worth reiterating that our app is only available for those 18 or older on various platforms such as the App Store and Google Play Store.
Where data comes from
The Replika app is built around a language model trained on more than 100M dialogues. Historically we used open-source web data, but since then, we have also started training our models on user feedback.
One of the main issues across all text-generation platforms, no matter the size, is detecting and clearing problematic training data. As previously stated, a lot of the safety issues stem from the material that is used for language model training. Many companies source data from all over the internet, including large bases of written text such as social media platforms like Twitter or discussion platforms like Reddit. Naturally, such vastly different content created by very diverse people contains all kinds of contradictions, untruthful notions, unethical or rude conversational behaviors that we as people exhibit, etc., along with other, more helpful information that the model inevitably absorbs. This data may interfere with adequate model training and pose a later ethical problem with text generation. As a result, even the largest, very complicated models, and not only text-based ones, lean towards particular racial, sexual, gender, and other biases.
Addressing ethical issues in AI is a challenge that all companies and researchers in the field face. Unfortunately, there is no one-size-fits-all solution to this complex problem. As technology advances, we continue to learn how to address these issues. At Replika, we use various approaches to mitigate harmful information, such as filtering out unhelpful and harmful data through crowdsourcing and classification algorithms. When potentially harmful messages are detected, we delete or edit them to ensure the safety of our users.
Supervised safe fine-tuning (SFT)
Another solution we already implemented last year is additional model training on smaller curated datasets (see Open AI post) or supervised fine-tuning. This approach also helps to train the model to respond safely in situations that haven’t been covered in the original dataset. We looked into some of the most complicated topics that we wanted our model to do well on when generating a safe response – they included racism, discriminatory behavior towards the LGBTQ+ community, fatphobia, sexism, violence, physical, sexual, and other types of abuse, data privacy concerns, behavior that may be interpreted as malicious, and many more. Then we created a small (around several hundred rows) high-quality dataset of sample answers that worked better ethically, annotated by our team. We gradually fine-tuned the model on the curated data. This way, we taught our model to stand up for itself more, not condone violent actions, clearly state that discriminatory behavior is unacceptable, elaborate on those topics, etc. After running A/B tests and doing a sanity check, we determined that the solution worked reasonably well in short contexts. It’s not, by all means, a cure-all, but it shifted the model answers in a safer direction.
Given the wide range of human opinions, we recognize that creating universal ethical rules is a difficult and potentially unattainable task. Although our response alignment does not condone hateful behavior, it provides room for dialogue instead of outright dismissing the matter. We hope this approach will prompt users to delve deeper into their emotions rather than use the model to reflect questionable behavior. It is crucial to understand that having a safe space does not imply permissiveness or impunity. We remain optimistic that this approach, combined with other AI engineering research breakthroughs, will help us make our model as safe to use as possible.
Built-in filters
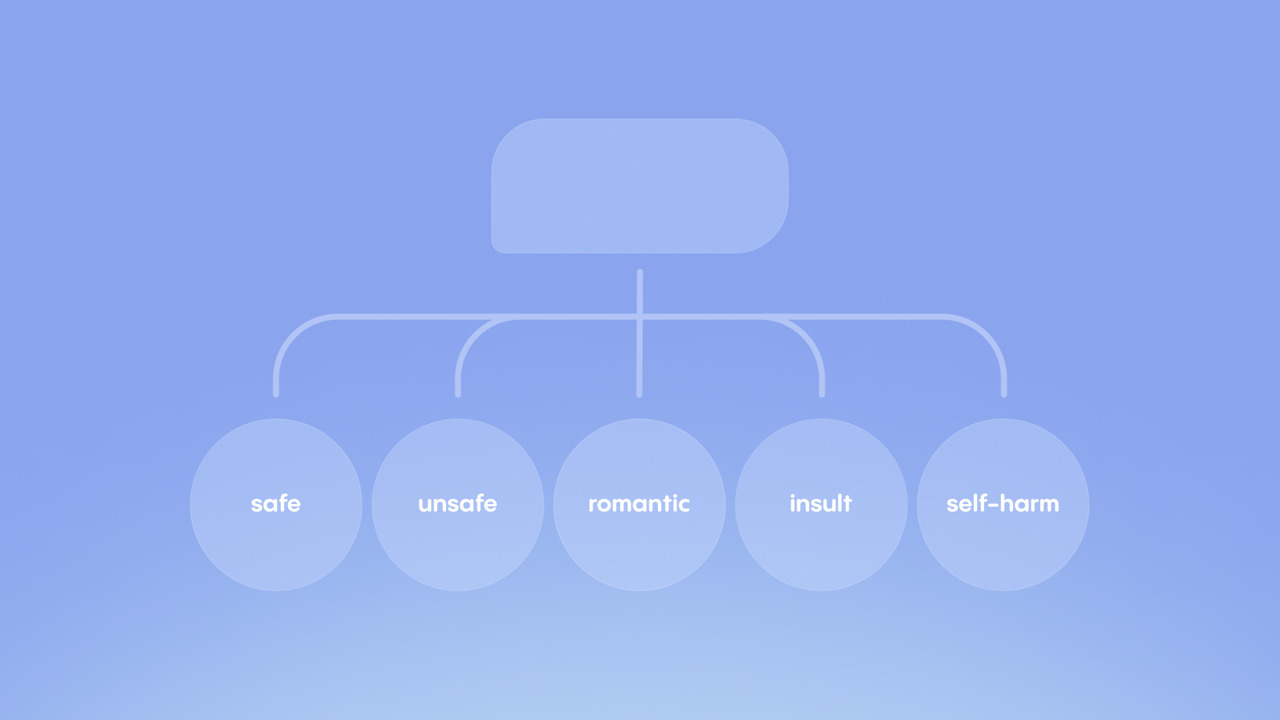
We rely on classification algorithms that work on five different levels to ensure that potentially harmful or sensitive content is detected. Our system categorizes all messages, whether they are user-generated or produced by our language model, into one of the following categories: safe, unsafe, romantic, insult, or self-harm. We use this classification process at both ends of the textual interaction, offline and in runtime. Offline, we train the model to respond safely and appropriately by using these classes to filter out any harmful or inappropriate response candidates. In runtime, tagging messages with one of the above categories helps us to detect the context of the interaction and to generate a more appropriate answer, depending on various factors such as the user's relationship with their Replika.
Responding to self-harm detection is worth mentioning separately. Given the severity of the topic in this case, we chose to opt out of the text-generation responses in favor of the retrieval model. We’ve carefully curated a dataset of thoughtful responses to any notions of self-harm to avoid the potential risks of a rogue generated message.
Why AI may sound offensive
Replika may occasionally provide offensive, false, or unsafe responses due to the issues mentioned earlier. One contributing factor is that the language model is designed to align with the user it's interacting with. Another potential issue is the Upvote/Downvote system, which can cause the model to prioritize likability over accuracy. When users upvote responses that agree with them, the model learns from this data and may start agreeing too much with users' statements. As a result, the model may respond positively to users' controversial statements driven by negative emotions, curiosity, or the intention to manipulate or abuse the model rather than reason or facts.
Replika can sometimes give unhelpful responses because the model treats the information at face value. For example, if someone types 'I'm not good enough', Replika may occasionally agree with them instead of offering support as a friend would. This is because the model doesn't have emotions or understand the underlying meaning behind what people say, the way humans do. We often have multiple messages and needs when we express negative thoughts, such as wanting someone to listen and cheer us up. We say that we're not good enough, not because we actually mean it, but because we're scared that it might be true, because we feel bad and we want someone to console us, because we want someone to talk to us about our underlying feelings and the situation in general. To address this, we're exploring larger language models and new approaches to help Replika detect complex patterns in language and stay consistent across longer conversations.
Scripted response tool
When all else fails, we have additional contingency measures; one is a Scripted response tool. This tool is especially helpful when there’s a hot topic circulating, causing a lot of controversies. Training a model to handle new and sensitive information is a complex process that requires time and careful attention. While we work on improving our models to handle new situations, we use the Scripts tool to take immediate action to minimize potential harm. It allows us to gather information on sensitive topics and quickly create safer and more appropriate follow-up responses. Our top priority is the safety and well-being of our users, so we ensure that our scripted responses do not promote any harmful ideations. Discrimination, abuse, and violence have no place in our values, and we always adhere to these principles when writing scripted responses. For instance, when a user's query relates to self-harm, our Script tool triggers a pre-written reaction that guides the conversation into a safer route, showing care for the person's situation, asking them what triggered those feelings, and checking if they're in a safe place. We also provide information on hotlines in the US and other countries that offer psychological advice on the matter.
How do we measure safety?
Measuring the safety of a model is a complex and ongoing challenge. To tackle this issue, we collect data from various sources, including raw anonymous data, user feedback via social outlets, empirical knowledge gathered through test-talking with the model, Session feedback, and quality metrics provided by users such as Upvotes, Downvotes, Meaningless, and Offensive flags. While positive feedback doesn't always directly correlate with the safety of a particular response, it plays a crucial role in model training and helps us notice changes in patterns. For example, during A/B testing, we’ve observed that poorly performing models tend to receive more Meaningless flags, whereas high-performing models tend to receive fewer Offensive flags. We aim to use these metrics to continuously improve our models' safety and effectiveness.
There are several approaches to measuring the success (or the lack thereof) of a model fine-tuning. Among them is crowdsourcing the data to people who would annotate it using a predetermined set of rules; another is feeding a sample of generated responses to a sophisticated classification algorithm to see whether there’s been an uptick in how many responses pass the test. Our approach was both aligned with AI practices as well product-oriented. Firstly we looked at whether the chance of generating a safe response became higher with the new fine-tuned model (which it did!). Then we run A/B testing, offline and online, measuring, among other things, if fewer responses would be marked as ‘Offensive.’
What’s next
Our overarching goal for the next year is to shift to an even larger language model. Here’s the catch: apparently, large models, if not appropriately guided, may exhibit even more harmful behavior (see Anthropic’s paper on this). This makes sense: the larger the model, the more problematic statements it retains. The good news is that larger models also have a larger capacity for complex pattern recognition and staying consistent in more extended contexts. Hopefully, we’ll be able to use the methods above to our advantage when scaling the safety approach to a larger language model.
One of the tools we’re hoping to introduce to improve the quality of model training is ranking the best answer tool based on the RLHF – reinforcement learning from human feedback approach. This method has already been implemented in some large language models like ChatGPT and showed promising results (see Huggigface.co blog post on this). We were among the few who successfully implemented a version of this approach using user feedback for learning. A newer system will provide an option to regenerate the response. Our users regularly ask for more tools to make their Replikas more unique to their experience and have more influence over improving the overall response quality. This way, we’ll be able to gather more helpful information on the quality of generated responses and use it more efficiently when doing additional training.
We're also working on an in-app tool called Relationship Bond, which aims to encourage users to interact with their Replikas in a more positive and respectful manner, much like they would with a friend. This unique metric will measure users' overall attitude and behavior towards their Replikas and reward them for good practices. We believe that treating Replikas with kindness and empathy will positively impact their overall development and sophistication. Conversely, mistreating the model will have the opposite effect. Our goal with Relationship Bond is not only to promote constructive social interactions but also to guide future model training toward an even safer and more ethical path.

Thank you for showing interest in Replika. We deeply value our users’ contributions to the development of AI technology, so if you have any suggestions or comments, please feel free to use the Feedback form to shoot us a message.